
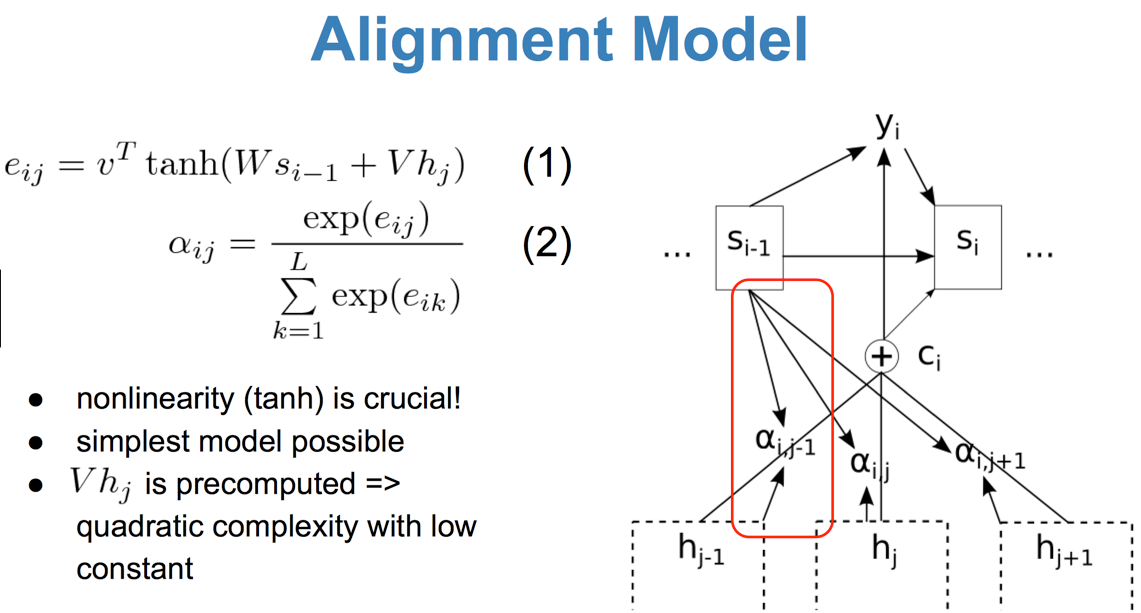
Attention-based Model (1)
What is attention?
In fact, the concept of “attention” in machine learning is just the same as what it is in our daily life. That’s maybe confusing. Imagine: parents always want their kids to concentrate, to focus on one thing they are doing, that’s the so-called “attention”. In other words, when we are reading a fiction story for example, sometimes we might can’t understand some parts. So we are likely to focus on this part more than usual, that’s also “attention”. However, before this concept, what people usually did in both language translation and recognition is just put the whole sentence or picture into the input and get the prediction.
Attention in NLP:
Let’s start with NLP task, in which “attention” is easier to understand. Here are two examples:
When we are doing natural language understand: A lot of people are gathering together to celebrate their wedding. From this sentence, we can infer that a couple just get married.
When doing machine translation:
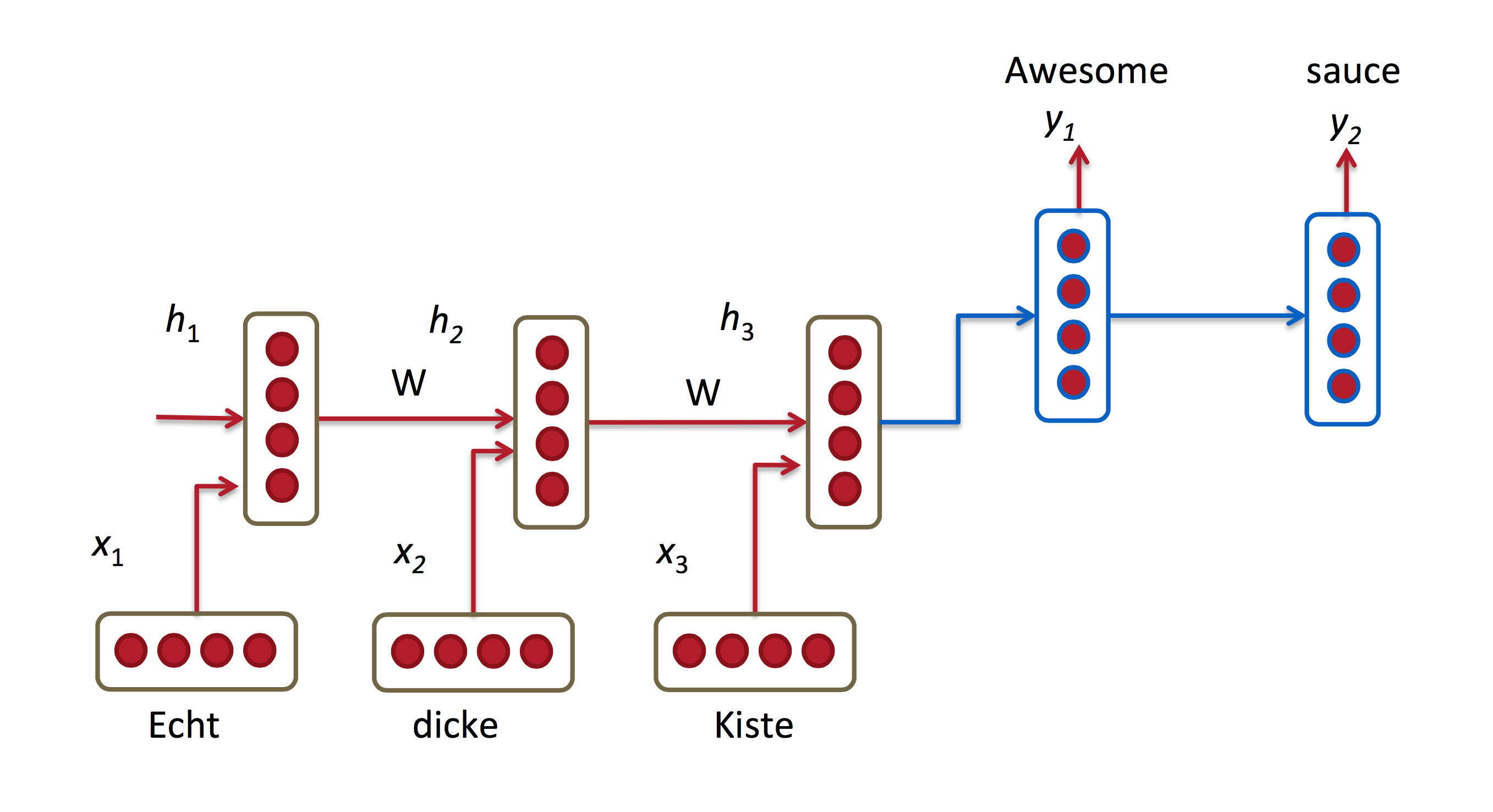
The main task of these two problems is modeling the conditional probability P(target|context) properly.
Take the above machine translation task for example, what Google used to do is : pass the context into a RNN encoder and get a context vector (the last hidden state of RNN). And then use another RNN decoder to generate every word in target one by one.
This sounds like a magic. However, the demerits are: No matter how long the input context is, it will always be compressed to a fixed-length vector. This means, larger input is , more information RNN gonna loses. This approach will get a poor result when the sentence becomes extremely long.
Following is the basic structure, which shows the power of Attention Based Model: simple but efficient:
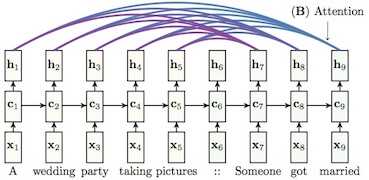
It means when generating target, all context vectors will be the input. Besides, another important point we should remember: we have to select proper context as the next state’s input Not all!!!.(To make it efficient) That’s also a major points of some on-going researches.
In other words, attention in fact is kind of content-based addressing mechanism. The goal is just to find out similar states as next information extraction. However, there are some many different practices to build attention-based model. In most papers, Attention is always represented by a weight vector, usually be the output of a softmax function. The dimension equals to the length of a context. Larger weight means context in this position is more important. I will talk about the details in next blog.